
Hi there!
せっかく、Coursera で Google Advanced Data Analytics Professional Certificate を取得したのと、もともとデータ分析スキルは応用してみたかったので、この度、実務で使ってみてます。
その辺りの経験を踏まえて、思ったことを徒然にメモしていきます。
いつも通り、自分への防備が目的の大半、そして、今、データ分析に興味を持っているどこかの誰かの参考に少しでもなれば幸いです。
データ分析の流れ
大体の環境において、若干の差異はあれどデータ分析は次の流れになります。
- データ分析の目的を明確にする
省略しがち、簡単なものでは明確だったりもする - データ収集または抽出
ここがめちゃくちゃめんどくさい大変 - EDA(Exploratory data analysis:探索的データ分析)
大まかに、「どんなデータ?」を理解する作業。+次のデータクリーニングの前段取り含む - データクリーニング
とても大事ですが、前のEDAをしっかりやっておけば、定型作業になります - データ分析(狭義の)
やっと本番、でもここまでくれば 7割方終わったようなもの - インサイトを得る
結論をまとめる - データの共有
データ分析に対する利害関係者へ適切に情報を伝達する(プレゼンがこのステップ)
実際に行った分析
さて、私が実務で行なった分析では、とある製品の製造工程において適用された不良品対策が果たして「統計学的に有意な差があるものか?」を分析しています。
「不良品が多数発生してしまう」という状況があり、困ってたものに対する処置です。製造業なんかの文脈ではよく遭遇するパターンといえます。
業務上のデータをオンライン上で公開はできないため、ふわふわした抽象的な説明とはなりますが、
概要としては、
- 不良品への対策済みデータ、対策未実施データをそれぞれ半年分(n=100ずつぐらい)使用
- 統計的仮説検定(ウェルチのT検定)を行なって有意差の判定。A/Bテストとも
- データ可視化ツールによる見える化
となります。
この場合、ステップ1のデータ分析の目的はかなり明確です。「不良品対策の効果があったかなかったか結論を出す」です。
ステップ2では、自社の EDI からダウンロードしてきたエクセルファイルをいい感じに、pandas でロードして DataFrame 形式に変換していきます。
この辺りは、Python でのプログラミングスキルの腕の見せ所です。
ウェブドライバーを使って、自動で必要なデータをダウンロードするような関数を作ってもよし、共有ディレクトリ上で必要なファイルのみを読み込むようなコードを組んでもよし、ケースバイケースです。
ステップ3では、データセットに対する大まかな理解が必要です。pandas の DataFrame オブジェクトでは、特に DataFrame.info() や DataFrame.describe() なんかのメソッドが有用です。
もちろん、データセットのビューで実態データの確認も大切です。この段階で、不要なデータセットの列には目星をつけておくと良いです。
ステップ4、データクリーニングでは、ごりごりデータを整理していきます。ここが結構大変です。EDA で不要と判断した列を DataFrame.drop() メソッドで落としたり、データタイプを適切に変換してあげたり、です。
このステップでいかに綺麗にしておくかが、データ分析全体の品質に直結します。
言い換えると、このステップさえうまくできれば、ほぼデータ分析も終わったようなものです。
そのために、このステップまででどれだけ泥臭くめんどくさい作業を行えるか、が肝要です。
データクリーニングでは、エクセルを利用してデータの集計を行なった経験がよく活きるはずです。
(実際、ただそれを Python コード上でやっているだけ)
ステップ5、狭い意味でのデータ分析、です。ここに関しては、データ処理ライブラリの機能とその目的をいかに理解しているかが重要です。
もちろん、データ分析における数学的な背景を理解することは重要ですが、実際には、そのような細かい計算はライブラリがほとんど自動で処理してくれます。
「どのプロシージャに、何をインプットすると、何が出力されるのか、そしてそれは何を意味するのか」の理解が特に大切です。
さらにいうと、英語ができると便利です。例えば、pandas のドキュメントだったり。
実際に行ったデータ分析では、分析対象としたそれぞれの要素間の相関係数の行列(相関行列)を求めたり、t統計量を求めたり、を行っています。
もちろん、適切なプロット(グラフ描画)で、どのデータの特性や要素同士の関係性あっているのかを視覚的に確認することも有用です。
いかにも「データ分析やってます」って作業で、やっていて楽しいです。
繰り返しになりますが、「データクリーニングまでにどれだけめんどくさい作業を行うか」が重要です。
ステップ6、データからインサイトを得るのは、特別複雑な問題でもない限り、データ分析をしながらやってしまうと思うので、特筆すべきことはないです。
もちろん、自分が行ったデータ分析を今一度振り返ってみるのは、良いことです。
ステップ7、データの共有を行う際に注意しなければならないことは、「データを共有する相手方が、あなたのデータまたはその分析の専門家とは限らないこと」です。
どれだけ優れたデータ分析であっても、それを解釈して利用するのは人間です。そして、分析結果を受け取る人間は、データ分析のスペシャリストだけではありません。むしろ、そのようなことは稀です。
つまり、いかに相手にわかりやすく伝えるか、です。ここに明確な正解はなく、数学が得意な人達にはそれなりの、現場作業をしている人には別の適切な伝え方があるはずです。
もちろん、忙しい経営者達に対して、細かいデータの積み上げから説明するのは悪手でしょう。もちろん、要求されれば見せるべきですが。もっと大きな要点から説明してあげたほうが喜ばれます。
ステップ5の(狭義の)データ分析を行っている最中に生成したグラフやチャートなんかを流用するのも有効です。
便利なツール
だいぶ大まかですが、上で、データ分析の実務での利用をしながら考えたことをつらつらと書いてます。
実際に使った便利なツール群と、(だいぶ主観的な)特徴を挙げておきます。
- pandas:Python におけるデータ分析ライブラリの王道です。この文脈において、ほぼ間違いなく聞く名前です。インターネット上の情報も豊富です。(英語も日本語も)
- seaborn:統計データの可視化用ライブラリ。後述の matplotlib よりも簡便に、定型的なグラフの描画が可能です。細かい設定しなくてもそこそこの見栄えのプロットを生成してくれます。
基本的なデータ分析であれば上記で事足りるでしょう。
これらは、プログラミング言語で例えるなら、より高級言語っぽいです。Python や JavaScript や Ruby みたいなイメージ。細かいことは気にせずにストレートにやりたいことだけできます。
もっと基本要素的で、アセンブリとかC言語みたいに小回りが効くものが以下
(要するに経験とスキルと細かい設定が必要なイメージ)
- NumPy:数値計算用ライブラリ、C言語で開発されていて、超高速。上述の pandas は NumPy 上で開発されています。
- matplotlib:上述の seaborn の内部で動いてます。もっと低レベルな描画ライブラリで細かい設定がだいぶ柔軟にできます。
その他、たまに見かけるライブラリを以下に追記しておきます。
(私はまだ学習以外使ったことがないので、知識が薄いです)
- scikit-learn:Python 環境の機械学習用ライブラリ。Google Advanced Data Analytics Professional Certificate や、Introduction to Machine Learning with Python など、Python x データ分析の文脈で圧倒的によく見かけます
- Plotly.py:インタラクティブなグラフを描画できるライブラリ。マウスカーソルをグラフ上に置くとデータラベルを表示したり、ズームしたり。Plotly 自体は描画ライブラリ全般を示し JavaScript, Python, R … などなど色々な環境で利用できるみたいです。
表計算ソフト(エクセルとか) と データ分析ライブラリの比較
表計算ソフト:
- 特別高度なスキルは不要
- 直感的でわかりやすい GUI 操作でほとんどのデータ分析ができる
- 一般的な企業ではほぼ確実に使われているので、どこでも利用できる
データ分析ライブラリ:
- それなりにプログラミング関係の知識が必要
- CLI に慣れてない人にはかなり苦痛
- 大容量のデータに対し、表計算ソフトよりも圧倒的に高速
- コードで処理を記述するため、適切に抽象化できていればコードの再利用が可能
- プログラミング言語を使うので、より複雑な処理も記述できる。
と、まぁ、主観的ですが、大体こんな感じです。
使い分けとして、
「日常的なデータ付き文書や小規模なデータ分析」は表計算ソフトの使いやすさや利便性に軍配が上がるでしょう。
その反面、
大量のデータ処理や複雑な処理は、データ分析ライブラリの得意とするところです。
データ分析実務では、
実際の分析作業までをデータ分析ライブラリで行う、データに対するインサイトの獲得やその共有は表計算ソフトで行う、といった流れが適切でしょう。
使用例
Jupyter Notebook か JupyterLab を利用している想定です。
簡便な説明のため、よく利用されるサンプルデータを利用します。
# グラフ描画ライブラリ seaborn を インポートし "sns" と別名付けする
import seaborn as sns# よく学習書なんかで使われる iris(花の一種) データセットを読み込み
# 変数 iris_dataset にバインド(保存)する。
# sns.get_dataset_names() で、他にもどのようなサンプルデータがあるのか一覧表示できる
iris_dataset = sns.load_dataset("iris")# 変数名のみ記述して実行することで、実体データを表示できる。
# Jupyter Notebook や JupyterLab で実行している前提
iris_datasetこんな感じに出力されるます
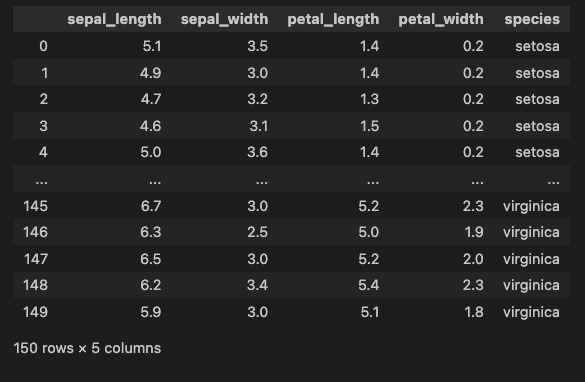
ちなみに、petal は花弁(花びら)のことです。
sepal は「萼片(がくへん)」のことらしいですが、あまり使わない単語なので、気になる人は、画像検索したほうがわかりやすいです。
要するに、”iris” データセットは、花の部位の「幅」・「長さ」・「種類」のデータを含んだ簡単なデータセットです。
データセットの概要を表示
iris_dataset.info()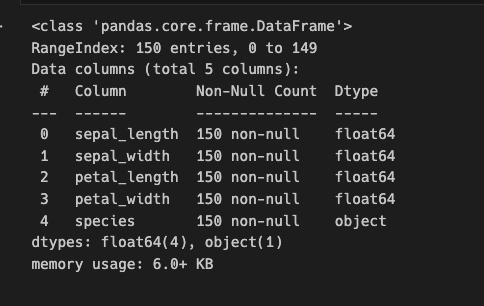
データセットの Descriptive statistics (記述統計量) を表示。
iris_dataset.describe()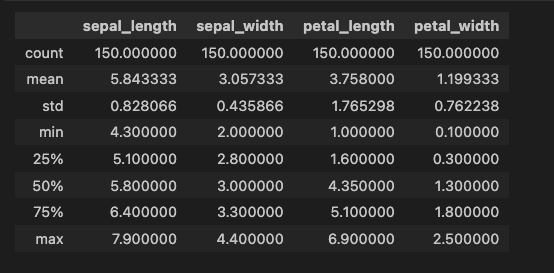
散布図(scatter plot)を描画
# data: 対象データセット
# x: プロットの x軸
# y: プロットの y軸
# hue: 色分けする種類
sns.scatterplot(data=iris_dataset, x="sepal_length", y="petal_length", hue="species")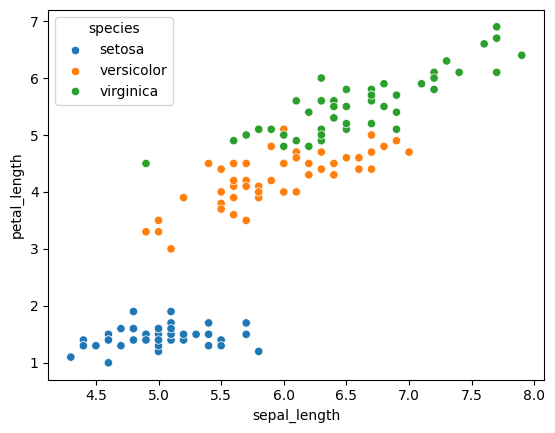
色々なデータの組み合わせで散布図をプロットする。
sns.pairplot(data=iris_dataset, hue="species")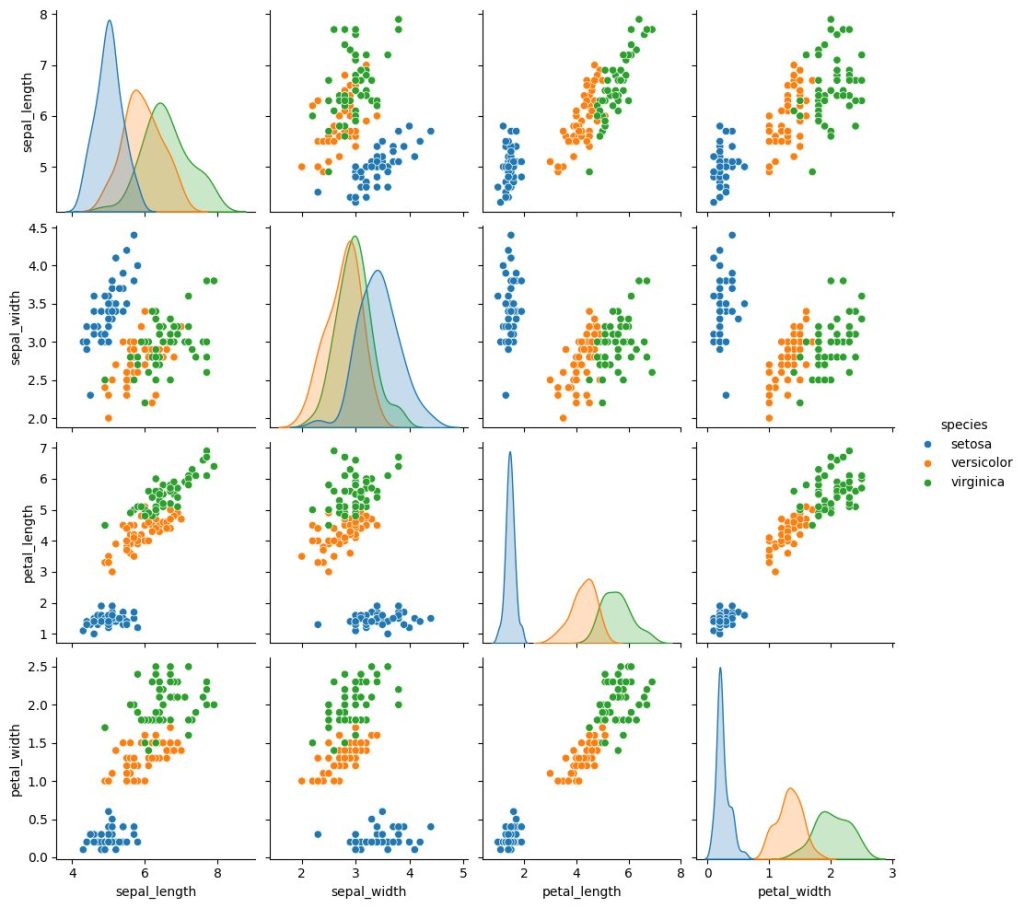
単純なデータのプロットを見るだけでも、花びら部位の「長さ」「幅」によって、iris の種類がうまく分類できることに気づくことができます。
まとめ
特に計画もなく、思ったことをつづっただけですが、慣れてしまえばほんの数行のコードで、それらしいデータ分析ができてしまいます。
上で述べたことの繰り返しになりますが、一番しんどいのは、データの収集とクリーニングの部分です。分析自体は楽しい作業になります。
なんとなく、seaborn のデータプロットを見ているだけで、業務のアレにもコレにも使えそうだな、と想像してしまえますね。
それでは、今日はこの辺で!
See you soon 🙂


コメント